MultiMediate 2026
Here, we introduce the different challenge tasks, evaluation methodology and rules for participation.
We provide links to official baseline implementations at the end of each challenge task description. Please be aware that these official baselines are usually just simple approaches. For the state of the art on each challenge task, please consult the challenge leaderboard.
For evaluation on all challenge tasks, please visit https://challenges.hcai.eu/web/challenges/challenge-page/29/overview.
Multi-domain Engagement Estimation
Knowing how engaged participants are is important for an artificial mediator whose goal it is to support human interaction. In MultiMediate'26, the engagement estimation challenge focuses on the development of approaches that generalise across different social situations, languages, age groups, and notions of engagement. For the NOXI, NOXI-J, NOXI (additional test languages), and MPIIGroupInteraction datasets, the task involves the continuous, frame-wise prediction of each participant's conversational engagement on a scale from 0 (lowest) to 1 (highest). In addition, MultiMediate'26 includes the PInSoRo dataset, which introduces categorical prediction targets for both social engagement and task engagement in child-child and child-robot free-play interactions. Participants are encouraged to investigate multimodal as well as reciprocal behaviour of all recorded individuals. We will evaluate predictions with the Concordance Correlation Coefficient (CCC) on datasets with continuous engagement annotations and with Cohen's Kappa on PInSoRo. The overall performance of a team will be evaluated by a weighted average of performances across test datasets. PInSoRo will receive a weight of 1/3, the four other datasets a weight of 1/6 each.
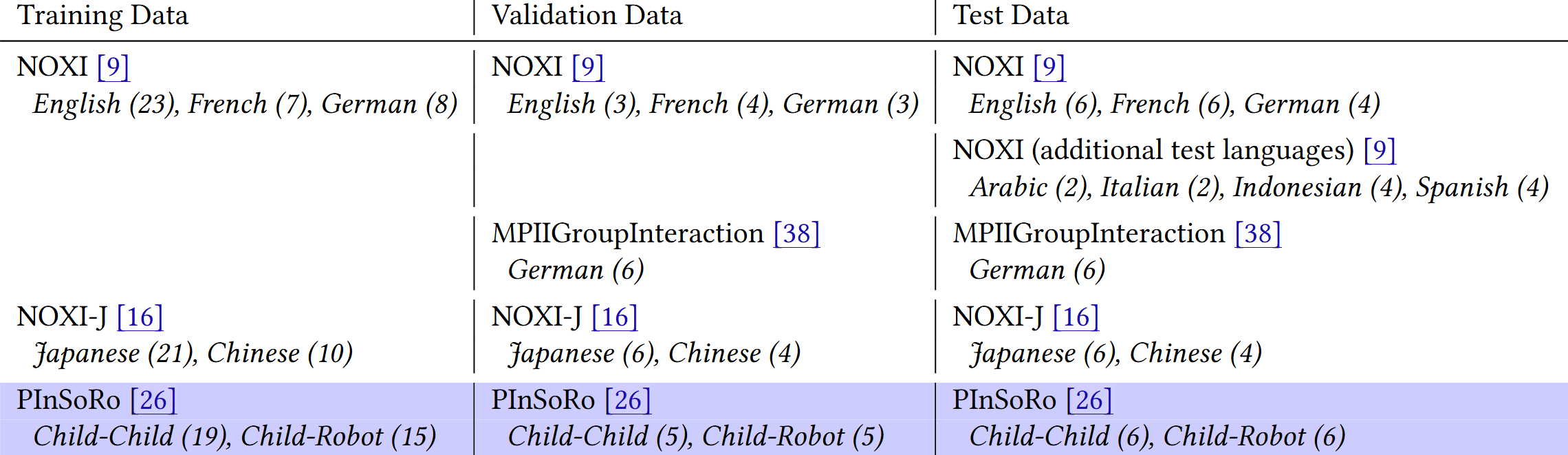
In the following, we present the datasets that are included in the challenge. All of them will be used for evaluation, while some are also available for training and validation. To take part in the challenge, participants need to submit predictions on all test datasets.
- NOXI (MultiMediate'23 version): A dataset of novice-expert interactions recorded with microphones and video cameras, with frame-wise engagement annotations. This dataset is identical to the engagement estimation challenge in MultiMediate'23 and consists of recordings in English, French, and German. Training, validation, and test sets are available.
- NOXI (additional test languages): This dataset is used as a test set only and includes four languages that are not part of the NOXI training set: two sessions in Arabic, two in Italian, four in Indonesian, and four in Spanish. As a result, this evaluation set tests the ability of participants' approaches to transfer to new languages and cultural backgrounds not seen at training time.
- NOXI+J: A dataset collected according to the NOXI protocol in Japan, featuring Japanese and Chinese speakers. It extends the cultural and linguistic diversity of the challenge and includes training, validation, and test sets.
- MPIIGroupInteraction: A dataset of multi-party group discussions. As in previous iterations of MultiMediate, engagement annotations are provided for the validation set to help participants monitor performance on this out-of-domain setting. The validation set may also be used as a limited amount of labelled data for supervised domain adaptation approaches.
- PInSoRo: A newly added dataset of English-language child-child and child-robot free-play interactions. In contrast to the conversational datasets above, PInSoRo contains categorical annotations for both task engagement and social engagement. Training, validation, and test sets are available. The inclusion of PInSoRo expands the challenge to a new age group, a new social situation, and a new interaction setting involving robots.
The following table gives an overview of the datasets used in the MultiMediate'26 engagement estimation challenge. Languages and subsets covered by each dataset are given in italics, with the respective number of interactions in parentheses. The datasets without highlighting were already part of MultiMediate'25, the novel PInSoRo dataset containing only English interactions is highlighted in blue.
For the multi-domain engagement estimation task, we provide the raw audio and video recordings along with a comprehensive set of pre-computed features for download. From the audio signal, we provide transcripts generated with the Whisper model and based on them sentence embeddings using XLM-RoBERTa. In addition we supply GeMAPS features along with wav2vec 2.0 embeddings. From the video, we provide OpenFace and OpenPose outputs to cover facial as well as bodily behaviour. We also provide the vision features extracted by VideoMAEv2, DINOv2 and ImageBind as well as contrastive language-image pretraining (CLIP) features. These features will be provided on all training and test portions of the data.
Official baseline approaches are available at https://github.com/hcmlab/MultiMediate26.
Continuing MultiMediate Tasks
In addition to the engagement estimation task described above, we also invite submissions to the three most popular tasks from previous MultiMediate iterations: bodily behaviour recognition, backchannel detection, and eye contact detection.
Bodily Behaviour Recognition
Bodily behaviours like fumbling, gesturing or crossed arms are key signals in social interactions and are related to many higher-level attributes including liking, attractiveness, social verticality, stress and anxiety. While impressive progress has been made on human body- and hand-pose estimation, the recognition of such more complex bodily behaviours is still underexplored. We formulate bodily behaviour recognition as a 14-class multi-label classification task. This task is based on the BBSI dataset (Balazia et al., 2022). Challenge participants receive 64-frame video snippets as input and need to output a score indicating the likelihood of each behaviour class being present. To counter class imbalances, performance is evaluated using macro-averaged average precision.
We explicitly encourage participants to evaluate their approaches on the related MAC challenge: https://sites.google.com/view/micro-action. Approaches showing convincing performance and generalization ability will have an advantage in the technical review.
Official baseline approaches are available at https://git.opendfki.de/philipp.mueller/multimediate23/-/tree/main/bodily_behaviour.
Backchannel Detection (MultiMediate'22 task)
Backchannels serve important meta-conversational purposes such as signifying attention or indicating agreement. They can be expressed in a variety of ways, ranging from vocal behaviour (“yes”, “ah-ha”) to subtle nonverbal cues like head nods or hand movements. The backchannel detection sub-challenge focuses on classifying whether a participant of a group interaction expresses a backchannel at a given point in time. Challenge participants are required to perform this classification based on a 10-second context window of audiovisual recordings of the whole group. Approaches are evaluated using classification accuracy.
Official baseline approaches are available at https://git.opendfki.de/philipp.mueller/multimediate22_baselines.
Eye Contact Detection (MultiMediate'21 task)
We define eye contact as a discrete indication of whether a participant is looking at another participant's face, and if so, who this other participant is. Video and audio recordings over a 10-second context window are provided as input to supply temporal context for the classification decision. Eye contact has to be detected for the last frame of the 10-second context window. In the next speaker prediction sub-challenge, participants need to predict the speaking status of each participant at one second after the end of the context window. Approaches are evaluated using classification accuracy.
Official baseline approaches are available at https://git.opendfki.de/philipp.mueller/multimediate22_baselines.
Evaluation of Participants' Approaches
Training and validation data for each sub-challenge can be downloaded at multimediate-challenge.org/Datasets/. We provide pre-computed features to minimise the overhead for participants. For MultiMediate'26, complete test sets without ground-truth labels will be provided to participants two weeks before the challenge deadline. Participants will then submit their predictions for evaluation on our servers. You can test your approaches on the test set at https://challenges.hcai.eu/web/challenges/challenge-page/29/overview.
For the engagement estimation challenge, approaches will be evaluated using CCC on the datasets with continuous engagement annotations and Cohen's Kappa on PInSoRo. Teams will be ranked based on the average performance across all engagement estimation test datasets. For the continuing tasks, bodily behaviour recognition is evaluated with macro-averaged average precision, while backchannel detection and eye contact detection are evaluated with classification accuracy.
Rules for participation
- The competition is team-based. A single person can only be part of a single team.
- For the cross-cultural multi-domain engagement estimation task, each team will have 5 evaluation runs on the test set.
- For the tasks that were already included in Multimediate'21-23, three evaluations on the test set are allowed per month. In May 2026, we will make an exception and allow for five evaluations on the test set.
- Additional datasets can be used, but they need to be publicly available.
- The organisers will not participate in the challenge.
- Complete test sets (without labels) will be provided to participants 2 weeks before the challenge deadline. It is not allowed to manually annotate any test data.
- To ensure reproducibility, sufficiently well-documented source code of the challenge solution needs to be made available.